12月5日讯,火山引擎今日推出全新升级的豆包语音识别模型2.0版本(Doubao-Seed-ASR-2.0),该模型基于先进的Seed混合专家大语言模型架构打造。
据了解,2.0版本在推理能力方面实现了显著提升,能够更深入地理解上下文关系,精准识别语音内容,关键词召回率相比前一版本提升了20%。
值得一提的是,该模型新增多模态视觉识别功能,不仅能够准确识别语音内容,还能结合图像信息进行文字识别,进一步提升了识别的准确率。

此外,2.0版本还支持包括日语、韩语、德语、法语在内的13种海外语言的精准识别。
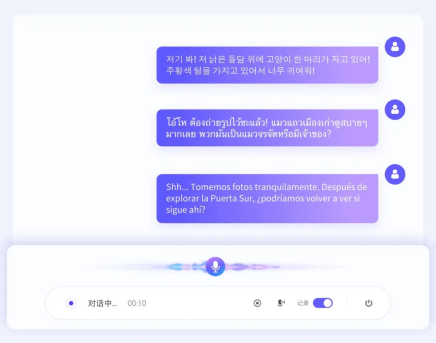
特别优化了对专有名词、人名、地名、品牌名称以及多音字的识别能力。
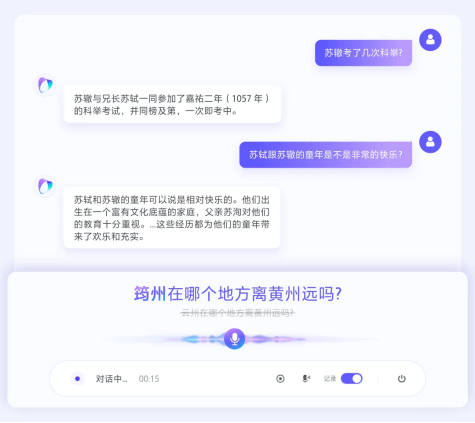
以历史人物讨论场景为例,当用户提到苏辙贬谪的筠(yn)州时,如果模型缺乏足够的推理能力,可能会将其误识别为郓州等同音字。而通过豆包语音识别模型2.0的智能推理能力,结合当前讨论的主题(如苏轼、苏辙),即使上下文中从未出现过筠州,模型也能准确识别出用户的真实意图。
目前,该模型已正式上线火山方舟体验中心,并通过API接口向外界提供服务。
(举报)
